


95% of AI Projects Fail to Deliver Measurable Value. I Spent Time Finding Out Why — and Built a System That Tries to Fix It.
Let us start with a number that most AI articles skip past. Gartner says 50% of GenAI projects were abandoned after proof of concept by end of 2025. MIT NANDA found that despite $30 to 40billion in enterprise AI investment, 95% of organisations were getting zero measurable return. BCG says only 5% of companies are achieving AI value at scale. These are not pessimistic outliers from fringe research. They are the consistent finding across three of the most cited institutions in enterprise technology. And they represent the reality that most product managers working on AI products are quietly navigating every single day.
What makes those numbers worth sitting with is not just their scale. It is how consistent the causes are across every report that examines them.
Three reasons AI projects keep failing — and why they are connected
The research points to the same failure patterns, across different firms, across different industries. Not as separate problems but as a connected chain, where each failure makes the next one more likely.
The first is what I call the value proof problem. Gartner, McKinsey, and BCG all arrive at the same root cause: AI projects fail not because the model is bad but because nobody built the system to prove it is working. There is no way to measure whether the model is hallucinating. No way to track whether its confidence scores are accurate. No documented reasoning behind the decision to ship or not ship a feature. No feedback loop connecting what happened after launch back to the decisions that led to it. The pilot looks impressive. The production system has no mechanism to know whether it is right. Without that mechanism, the gap between the demo and the real product stays open indefinitely.
Because that gap stays open, the second failure follows naturally. Call it the trust and safety problem. IBM found that 60% of organisations either have no artificial intelligence governance policies or are still in the process of developing them. OWASP, the organisation that publishes the most widely referenced security risk frameworks for software, names prompt injection and unsafe agent actions as live threats in systems that are already running in production. McKinsey found that user trust in artificial intelligence is not solved by making the model more accurate —it requires explicit escalation design, governance frameworks, and human override logic built into the product from the start. Most artificial intelligence products ship without any of this. When they fail, they fail without warning and without a documented path to recovery.
Both of those failures feed into the third. Gartner cites escalating costs as a primary reason project are abandoned after the proof-of-concept stage. MIT NANDA found that failures happen specifically because tools do not integrate into existing enterprise workflows and do not learn from feedback over time. A system that cannot prove its value, cannot be trusted at scale, and
does not reduce its own cost over time does not graduate from pilot to production. It stays a pilot until the budget runs out.
These three failures are not independent. They are a chain. And together they explain why the failure rate is 95%.
What the research says about the product manager’s role — and the gap it leaves
The research is consistent on the direction of change too. Product managers need to shift from being executors — people who coordinate work and manage delivery — to orchestrators —people who design the systems that make decisions and govern how those systems behave. Gartner describes this shift in their 2025 strategic predictions. McKinsey recommends that organisations institute enterprise-wide orchestration functions to manage artificial intelligence at scale. Walmart’s Chief Product Officer Tim Simmons said on stage at ProductCon in 2025 that the product manager’s job is now about harnessing fleets of agents so that scale becomes a competitive advantage rather than a source of fragility.
There is a fourth dimension to this shift that the research gestures at but rarely states plainly. Product managers are increasingly expected to build proof of concepts themselves — before an idea ever reaches an engineering team. At Meta, product directors have described PMs using AI tools to prototype full applications in hours and presenting them directly to leadership for rapid iteration. Lenny Rachitsky, one of the most-read voices in product management, published a dedicated guide in January 2025 on how PMs can turn ideas into working prototypes in minutes. The expectation is no longer that a PM describes what to build — it is that a PM can demonstrate it. That shift changes what it means to be technically credible in the role. It was one direct reason this system was built the way it was: not by handing a specification to engineers, but by building the thing first.
The direction is clear. The gap in the research is also clear.
None of these reports show what orchestration actually demands when you sit down to build it. It demands decisions that do not appear in any product requirements document and are not covered by any framework in circulation. Deciding what an artificial intelligence agent is allowed to decide on its own versus what must be reviewed by a human. Setting the confidence threshold at which a system stops trusting itself and asks for help. Defining what the system should remember across decisions and what it should discard. Recognising when an artificially high confidence score is a product risk rather than a product feature. Building the governance layer that sits between what the model outputs and what the user actually sees. Every one of these decisions requires having built something real to understand it. They cannot be learned from are search report. And very few product managers have built them.
That gap between what the reports describe and what building it actually demands is what this series is about.
What I built — and why each part connects to a real failure
To close that gap, I built a living, self-improving multi-agent artificial intelligence system that manages the full intelligence cycle of an artificial intelligence product: from discovering user pain through to monitoring the product after launch. Every component was designed as a direct response to one of the three failure clusters described above.
To address the value proof problem, I needed a system that evaluates model quality on dimensions most product managers have never had to measure, and that makes documented go or no-go decisions with explicit confidence scores and full reasoning chains. To address the trust and safety problem, I needed a governance module, a security layer, and human escalation logic built into the architecture from the beginning — not added later when something went wrong. To
address the operating model problem, I needed a memory system that learns from every past decision, and cost intelligence that makes the unit economics of running the system visible and controllable. Four stages. Nine agents. One feedback loop.
I used AI to generate the Python code throughout this build. That part was never the point. The point was the thinking above the code — deciding what to build, in what order, with what constraints, and why. The decisions about what the system is allowed to do on its own, when it must ask a human, what it should remember, and what should happen when it is confidently wrong. Those decisions are what this series is actually documenting.
High Level System Architecture
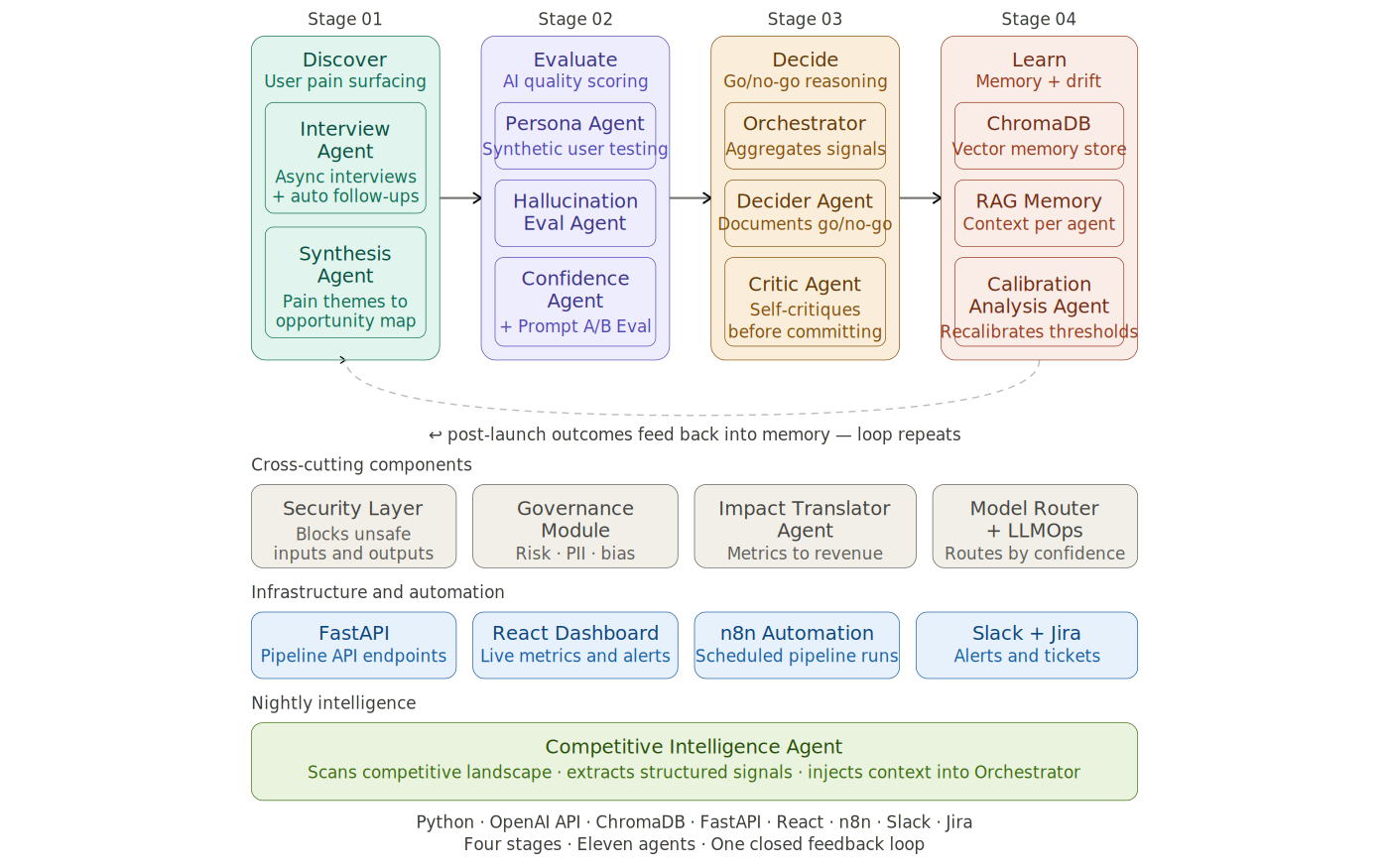
The four stages — and the question each one left open
Each stage was built to solve a specific problem. Each one immediately surfaced a harder problem underneath it. That pattern — solving one thing and uncovering the next — is the honest experience of building an artificial intelligence system from scratch. It is also the structure of the eleven posts that follow this one.
Stage 01 — Discover
The Interview Agent conducts asynchronous user interviews with automatically generated follow-up questions and saves transcripts as structured data. The Synthesis Agent reads all transcripts, identifies the most significant pain themes, scores them by how frequently they appear and how severe they are, and produces an opportunity map. This addresses the failure mode where user research gets simplified and stripped of nuance before anyone acts on it — the gap between what users actually said and what ends up on the product roadmap.
Building this immediately raised a harder question. When the Synthesis Agent started weighting certain user segments more heavily — not because those users had more pain but because their interviews produced more text — was the system finding real signal or reflecting a flaw in how the data was collected? That question changed how the system was designed. Post 2 covers what was found and what it means for any product manager building user research into an artificial intelligence pipeline.
Stage 02 — Evaluate
The Hallucination Evaluation Agent scores outputs on two dimensions that most teams treat as the same thing but that require completely different approaches to detect. The Confidence Agent measures the gap between how confident the model says it is and how often it is actually right. The Prompt testing system versions every prompt, runs the old version and the new version against the same fixed test cases, and automatically promotes the version that performs better. Together these address the question that the majority of product teams skip: how do you actually know the artificial intelligence is good enough to ship?
Catching hallucinations turned out to be the easier half of this problem. The harder half was the gap between the model reporting high confidence and actually deserving that confidence. That gap is not just a quality issue. It is an operational risk, because an overconfident model will not escalate to a human when it should. Post 3 explains how that gap was measured and what was done to close it.
Stage 03 — Decide
The Orchestrator brings together all signals from the first two stages into a single confidence score and passes everything to the Decider Agent. The Decider produces a documented go or no-go recommendation with a confidence score, a full reasoning chain, and a flag indicating whether the decision should go to a human. Before that decision is committed, the Critic Agent reviews the reasoning. If the critique score falls below a defined threshold, the decision goes back for revision. After two failed revision attempts it is routed to a human for review. This is the orchestrator role made concrete — not as a concept but as working architecture with a testable threshold and a documented escalation path.
The most uncomfortable design decision in the entire system was choosing that threshold. Set it too low and the system become an expensive way to generate human work. Set it too high and you are shipping false confidence into a production environment. Post 5 walks through exactly how that number was arrived at — and honestly acknowledges what remains uncertain about it.
Stage 04 — Learn
Every interview transcript and past decision is stored as a vector embedding in a local database. Before every agent acts, the memory system retrieves the three most semantically relevant past decisions so that every future decision is informed by what the system has already seen and learned. Every decision is logged with its input signals, reasoning chain, confidence score, model used, computational cost, and eventual outcome. Post-launch signals and drift indicators feedback into memory automatically.
A system that learns from past decisions sounds like a straightforward advantage. It is not always. Post 6 examines what happens when the memory retrieves a past decision that was wrong — and treats it as reliable guidance for the current one. That failure mode is harder to detect than hallucination and compounds over time in ways that are difficult to reverse.
What the eleven posts teach — two ways to read this series
The posts that follow cover both the technical and the strategic dimensions of these problems.
Every post is written so that both audiences get something concrete. The technical reader gets working code and architectural decisions with documented trade-offs. The strategic reader gets the decision above the code — what it means for how a product manager hires, governs, and ships artificial intelligence products responsibly.
For technically oriented readers, the posts answer questions like: What does a hallucination actually look like when it influences a real product decision? How do you build a system that knows when to stop trusting itself? What does agent security look like in working code when prompt injection is a genuine threat? How do you version prompts the way engineer’s version code — and why does a single regression matter? How do you build cost intelligence that makes model routing a principled decision rather than an instinctive cost cut?
For strategically oriented readers, the posts answer questions like: How do you make a go or no-go call when the data is ambiguous and the artificial intelligence system is confident? What does responsible artificial intelligence governance look like when it is built into a running system rather than written into a policy document? When should a system escalate to a human — and when is that just a way of avoiding accountability? How do you measure artificial intelligence quality in terms a leadership team understands, not just metrics an engineer can calculate? How do you build the internal case for artificial intelligence infrastructure before the return on investment is visible?
The honest observation this series is built on
Building this system required using artificial intelligence to generate Python code throughout. That was never the interesting part. The interesting part was every decision that sat above the code — what the system should decide on its own, what it should escalate, what it should remember, what it should never be allowed to do, and what should happen when it is confidently wrong. Those decisions are what the research calls orchestration. They turned out to be harder, more specific, and more consequential than any report had prepared me for. The gap between what the literature describes and what the build actually demands is what this series documents— as honestly as I can.
Before you read Post 2
The 95% failure rate is not a mystery. It is the predictable outcome of building artificial intelligence products without the systems to evaluate them, govern them, or learn from them over time. The question is not whether the organisations you work in or advise are somewhere in that number. The question is what it would actually take to move out of it. These posts are one honest attempt at that answer, written down as clearly as possible. Whether it holds up is something you can judge for yourself as the series unfolds.
The full codebase — eleven agents, four pipeline stages, every architectural decision documented with its trade off and the condition that would make me reverse it — is on GitHub: https://github.com/saurabhsmahajan/ai-product-loop.
The README is written with a decision log, not only as an installation guide. Start there if you want the architecture before the narrative.
Sources
Gartner — Top Strategic Technology Trends 2025 50% of GenAI projects were abandoned after proof of concept by end of 2025. Gartner also predicts that over 40% of agentic artificial intelligence projects will be cancelled by end of 2027 due to rising costs, unclear business value, and complexity. Additionally, 40% of enterprise applications will be integrated with task-specific artificial intelligence agents by end of 2026, up from less than5% in 2025. Source: gartner.com/en/newsroom
MIT NANDA — Enterprise AI Value Report 2025 Despite $30 to 40 billion in enterprise GenAI investment, 95% of organisations were getting zero measurable return. Only 5%were extracting meaningful value at scale. Source: Referenced in enterprise AI adoption coverage, 2025
BCG — AI at Scale Report 2025 Only 5% of companies are achieving artificial intelligence value at scale. 60% are not achieving material value at all despite significant investment. Source: BCG research on generative AI value creation, 2025
McKinsey — State of AI 2025 and AI in the Workplace 2025 AI adoption is widespread but scaling impact remains a work in progress. High-performing artificial intelligence organisations are significantly more likely to define when model outputs need human validation, measure outcomes rigorously, and invest in governance and operating model design alongside technology deployment. McKinsey also recommends that organisations institute enterprise-wide leadership and orchestration functions to manage artificial intelligence at scale. Source: mckinsey.com/capabilities/tech-and-ai
IBM — Cost of a Data Breach Report 2025 60% of organisations either have no artificial intelligence governance policies or are still developing them. Only 37% have artificial intelligence access controls in place. In India specifically, IBM reported that nearly 60% of breached organisations lacked artificial intelligence governance, and shadow artificial intelligence usage was linked to measurable increases in breach cost — adding up to$670,000 to the average breach. Source: ibm.com/reports/data-breach
OWASP — LLM Top 10 2025 The Open Worldwide Application Security Project’s framework for large language model security names prompt injection, insecure output handling, excessive agency, and sensitive information disclosure as the most critical security risks in production artificial intelligence and agentic systems. Source: owasp.org/www-project-top-10-for-large-language-model-applications
Walmart Chief Product Officer Tim Simmons — ProductCon 2025 “Product managers are shifting from pure problem solvers to artificial intelligence orchestrators. Our job now is to harness fleets of agents and all of our complexity so that scale becomes a competitive advantage instead of something that slows us down.” Source: Product School ProductCon,2025. Also referenced in: buzzsprout.com/90361/episodes/18691272
Gartner — Top Predictions for IT Organisations, October 2025 Standardised workflows are being replaced by context-driven orchestration. By 2027, fragmented artificial intelligence regulation will grow to cover 50% of the world’s economies, driving $5 billion incompliance investment. Artificial intelligence transformation is increasingly being built on artificial intelligence governance as a foundation. Source: gartner.com/en/newsroom/press-releases/2025-10-21-gartner-unveils-top-predictions
Forrester — Readying Product Management for Success in the Age of Digital and AI,2025 Digital business leaders identify analytical thinking, creativity, and a detailed vision focused on customer outcomes as critical success factors for artificial intelligence and digital product initiatives. The product manager role is central to evaluating opportunities and leading the effort to build solutions that drive increasing value for both customer and business. Source: forrester.com/report/readying-digital-product-management-for-success
Business Insider / Meta — November 2025 Product managers at Meta’s Superintelligence Labs are building and demoing prototype applications using AI coding tools before passing ideas to engineering teams. Joseph Spisak, product director at Meta’s Superintelligence Labs, described the practice: “We can literally vibe code products in a matter of hours, days, and explore the space.” A non-technical Meta PM separately told Business Insider that AI tools gave him the capability to execute directly, not just coordinate. Source: businessinsider.com/meta-vibe-coding-build-prototype-apps-mark-zuckerberg-2025-11
Lenny’s Newsletter — January 2025 “A guide to AI prototyping for product managers: How to turn your idea into a working prototype in minutes.” One of the most-shared product management pieces of 2025, it directly addresses the expectation that PMs can build functional prototypes independently using AI tools. Source: lennysnewsletter.com/p/a-guide-to-ai-prototyping-for-product