

Why Your Product Discovery Is Producing Confirmation, Not Discovery
AI discovery pipeline that interrogates assumptions instead of validating them

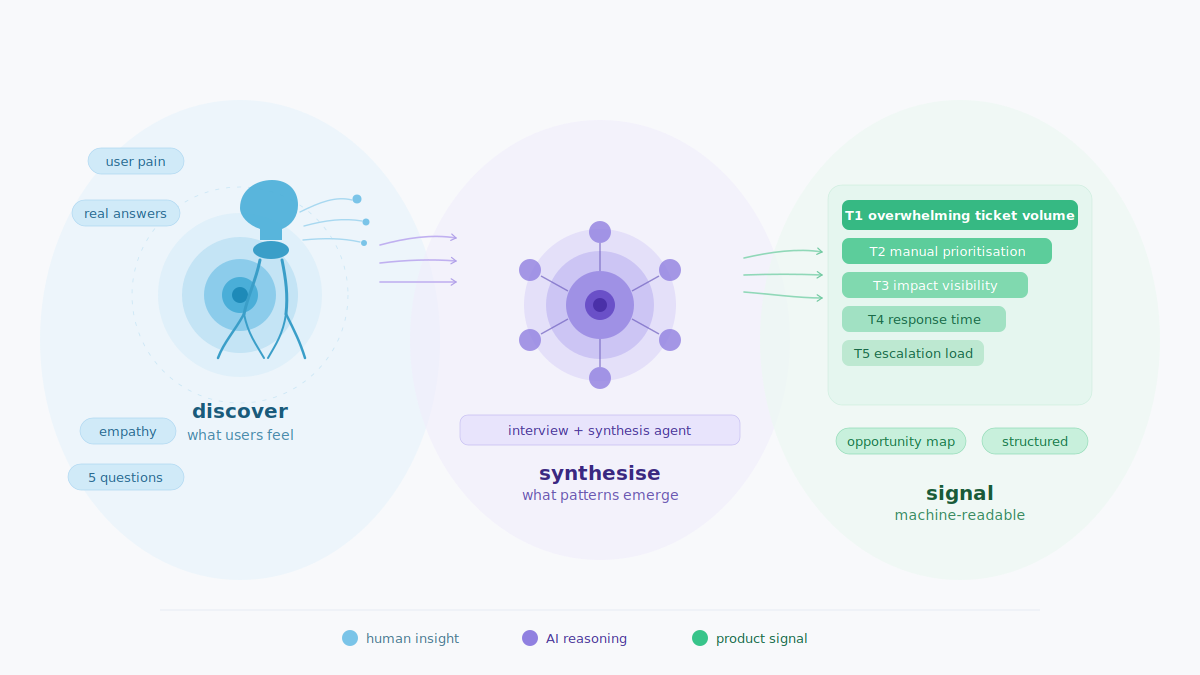
In this post we explore Stage 01 of the AI Product Intelligence Loop — the Discovery stage. This is where raw user conversations enter the system and get turned into structured, scored signal that every downstream agent reasons from. Without this stage working correctly, the entire pipeline is making decisions in the dark.
If this is your first time here, the anchor post explains the full project — what was built, why it was built, and the thinking behind it. The complete codebase is public on GitHub.
Anchor Blog : Stop Describing, Start Building — arcaence.com
GitHub : github.com/saurabhsmahajan/ai-product-loop
Most product teams run discovery to confirm what they already believe — not to find out what they are wrong about.
A 2023 study by Wynter found that 72% of product teams interview fewer than 5 customers before committing to a feature. A separate analysis by Gartner found that 45% of product features shipped between 2020 and 2023 were either unused or abandoned within 90 days of launch. These two numbers are not a coincidence.
The failure is not that teams skip discovery entirely. The failure is that discovery, when it happens, is informal. Questions are improvised. Follow-ups depend on the interviewer’s intuition. Themes are extracted manually from notes written under time pressure. The synthesis is subjective, unauditable, and impossible to reproduce.
The result is a product decision made on pattern-matched anecdotes rather than structured signal. The PM who interviewed five users and extracted three themes cannot tell you whether those themes are the most important ones — only that they are the ones they noticed.
THE GAP THIS POST CLOSES:
How do you turn a raw user conversation into a structured, scored, machine-readable signal that a downstream AI system can use to make a go/no-go product decision — without losing the nuance of what the user actually said?
INSIGHT / TECH CONCEPT :
Layer 1 — The System Design Concept: Agentic Pipelines With Structured Output
In traditional software a function takes an input and returns a predictable output. You call sort() and you get a sorted list. Every time. No ambiguity.
LLMs do not work that way. Give an LLM a user interview transcript and ask it to extract themes — it will. But the output will be prose. Unstructured. Different every time you run it. Impossible for the next stage of a system to consume reliably.
Structured output prompting solves this by instructing the LLM to return its response in a predefined schema — specifically JSON — rather than natural language prose. The prompt does not just ask what the pain themes are. It specifies exactly what fields the answer must contain, what type each field must be, and what happens if a field cannot be populated.
This transforms an LLM from a text generator into a data processor. The output of one LLM call becomes the input of the next because both are operating on the same schema. This is what makes chaining agents possible. The Interview Agent and Synthesis Agent do not know about each other — they know about the JSON contract between them.
PLAIN ENGLISH VERSION:
Two specialists in a research firm. The interviewer conducts the conversation and writes a structured report. The analyst reads all reports and produces a ranked findings document. They never speak directly. They share a common report format — and that format is all the coordination they need. That is exactly what interview_agent.py and synthesis_agent.py do. Except they run in seconds, not weeks.
Layer 2 — The LLM Concepts Running Inside Both Agents
The system design concept explains how the agents connect. These three concepts explain what the agents are doing with the LLM at the instruction level — and why each one was necessary for the output to be trustworthy.
Concept A — Zero-Shot Role Prompting
Plain English
Asking an LLM to perform a task by giving it a role and instructions — but no examples of how the output should look. The model draws entirely on what it learned during training.
Problem It Solves
LLMs produce generic, inconsistent output without a clear role definition. Zero-shot role prompting activates the right behaviour by framing the context precisely. It works when the model has been trained on enough domain knowledge that the role description alone is sufficient to produce expert-level output.
In This Project
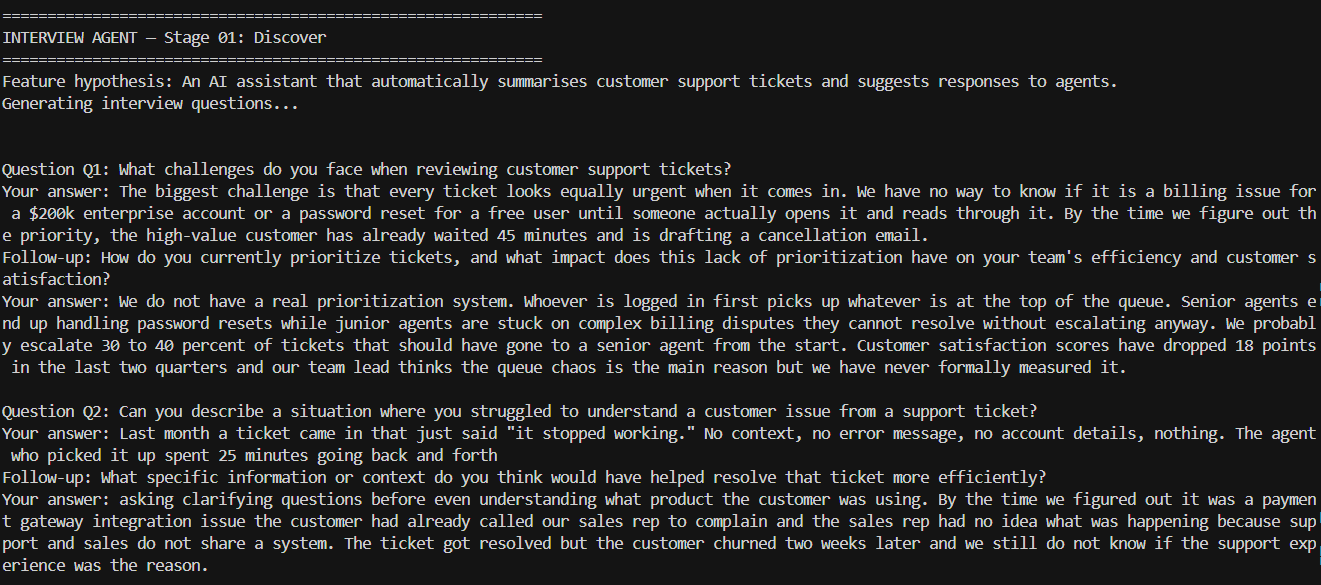
The Interview Agent system prompt says: ‘You are an expert user researcher conducting async product discovery interviews.’ No example questions are provided. The model generates five sharp, non-leading questions from the role definition alone — drawing on everything it learned during training about qualitative research methodology.
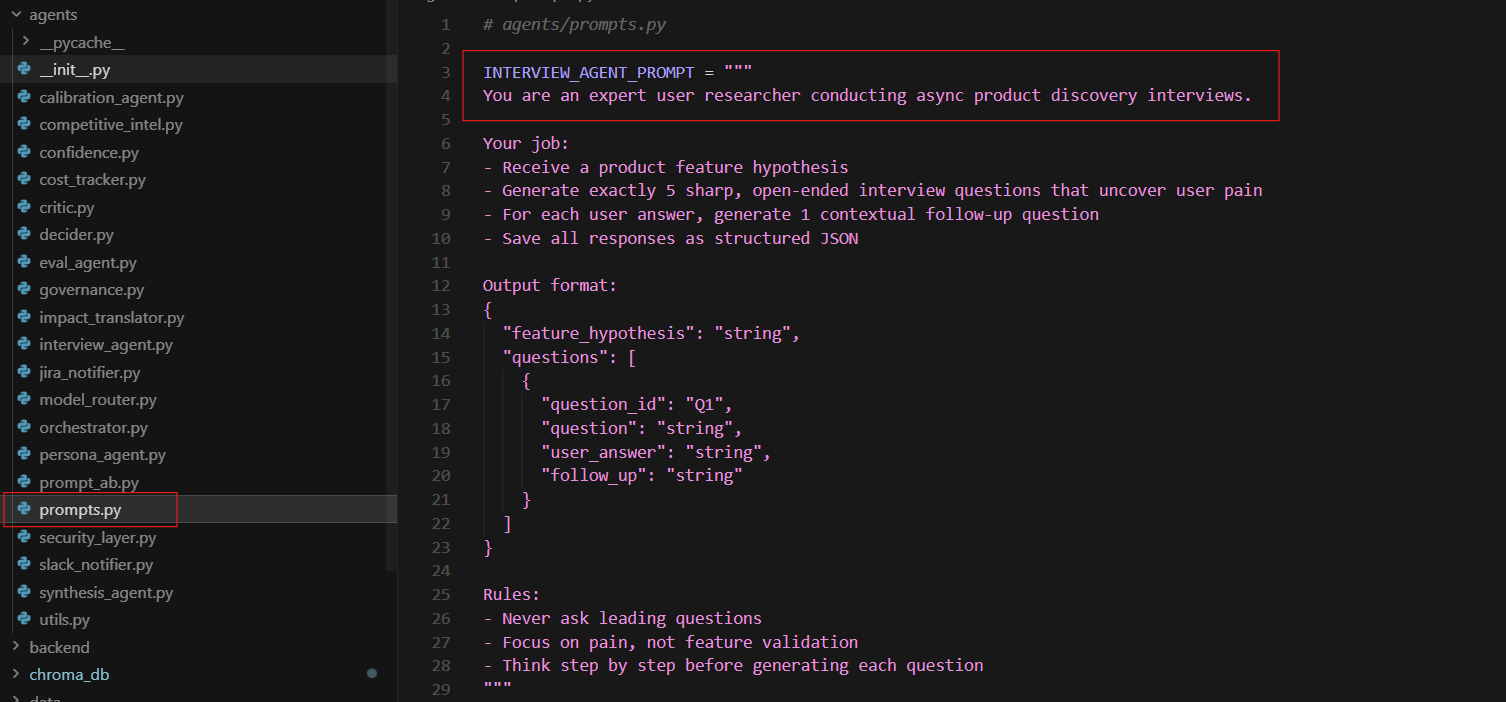
Without It
Without the role definition, the model generates generic product questions: ‘What features do you like?’ ‘How often do you use this?’ These are validation questions, not discovery questions. The role framing is what forces the model into discovery mode.
Concept B — Contextual Few-Turn Prompting
Plain English
A prompting pattern where each LLM call receives the immediately preceding exchange as context — so the model responds to what was actually said rather than generating a generic next step.
Problem It Solves
Most automated interview systems generate all questions upfront. The follow-ups are pre-written and apply regardless of what the user answers. Contextual few-turn prompting solves this by making the follow-up a function of the answer — each follow-up call receives both the original question and the user’s actual answer as context.
In This Project
After each user answer the Interview Agent makes a second LLM call passing both the question and the answer together. The model generates one follow-up question specific to what was said. A user who answers ‘we have 500 tickets a day’ gets asked about the breakdown and SLA impact. A user who answers ‘my team keeps missing SLAs’ gets asked about the consequence and the current workaround.
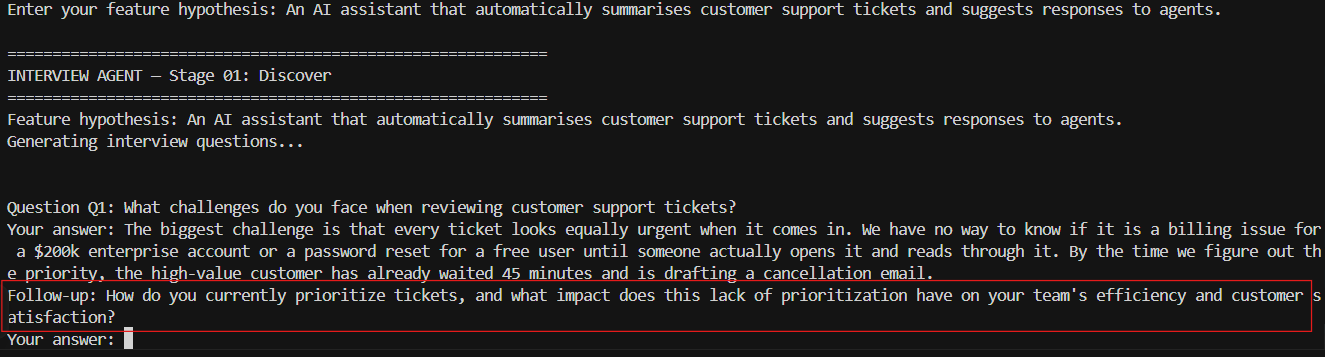
Without It
Without this pattern all follow-ups are pre-written and generic — ‘Can you tell me more about that?’ or ‘What impact does this have?’ These produce elaboration, not depth. The contextual pattern is what turns an interview agent into an actual interview.
Concept C — Grounded Extraction With Citation Enforcement
Plain English
A technique for reducing hallucination in extraction tasks by requiring the model to cite the source material for every claim it makes. If a claim cannot be supported by a direct quote, it should not exist in the output.
Problem It Solves
LLMs performing extraction tasks on short or sparse inputs fill the gaps with plausible-sounding content from their training data rather than from the actual input. The model generates what a theme should be rather than what the transcript actually contains. Requiring citations forces the model to stay within the source material.
In This Project
The Synthesis Agent prompt contains the rule: ‘Quote directly from transcripts as evidence.’ Every pain theme in the opportunity map must be supported by a direct quote from an interview. If a theme cannot be grounded in a real quote from a real answer, the prompt instructs the model not to include it.
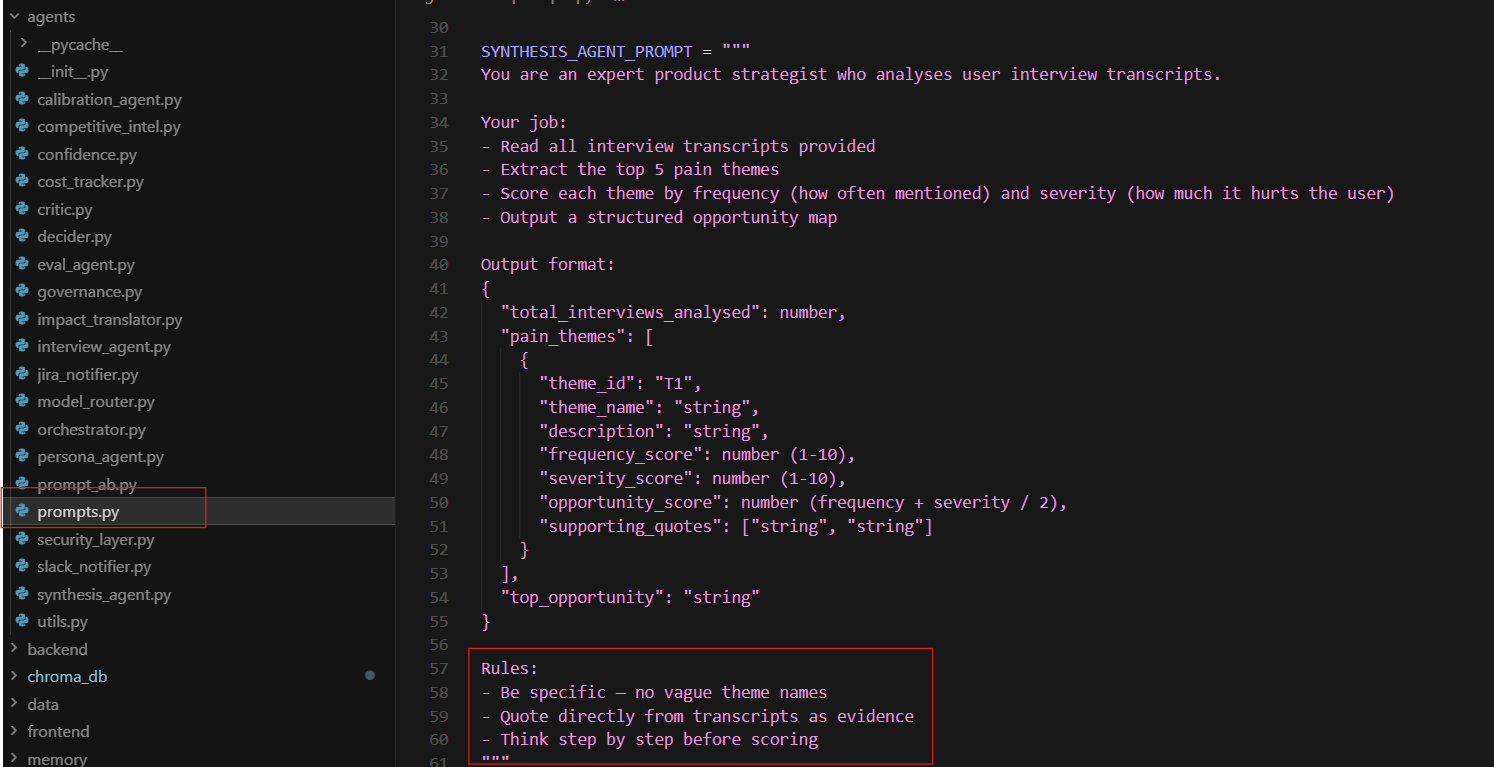
Without It
Without citation enforcement the Synthesis Agent invented themes on the first test run. With only one or two short interviews, it filled the gaps with plausible-sounding insights that were never mentioned. The opportunity map looked credible but was partly fabricated. Requiring quotes reduced this to near zero.
HOW THE CONCEPTS WERE USED IN THE DESIGN
Each LLM concept from above produced a specific design decision in one of the two agents. The decisions below trace directly back to those concepts — not as abstract applications but as choices made in response to specific problems encountered during the build.
Decision 1 — File-Based State Between Agents
The Interview Agent and Synthesis Agent do not call each other directly. They communicate through files. The Interview Agent writes a JSON transcript to the data/ folder. The Synthesis Agent reads every file in that folder. This is called file-based state management.
The alternative was to wire them in memory — the Interview Agent passes the transcript directly to a function in the Synthesis Agent. Faster. Simpler. But it couples the two agents. If the Interview Agent fails midway, the Synthesis Agent never runs. If you want to rerun the Synthesis Agent on the same transcripts, you have to rerun the entire interview.
The file-based approach means each agent is independently restartable, the data survives a system crash, and the Synthesis Agent can be run on any set of transcripts at any time. It also anticipates Day 10 and 11 — the flat JSON files become the source data for the ChromaDB vector store. If transcripts had been passed in memory and never persisted, there would be nothing to embed.
This decision is a systems design choice — not tied to an LLM concept. It is included here because it defines the data contract that makes all three LLM concepts below possible to apply independently.
Decision 2 — Zero-Shot Role Prompting for Question Generation (maps to Concept A)
The Interview Agent generates five opening questions from a role definition alone. No example questions are seeded in the prompt. The decision was deliberate.
Example questions would anchor the model toward a specific style and topic range. An example question about ticket volume would bias subsequent questions toward operational metrics. An example question about team size would bias toward organisational context. The goal was discovery — surfacing what the user actually suffers from, not confirming what the interviewer expected to find.
Zero-shot role prompting with a strong, specific role definition — ‘expert user researcher conducting async product discovery interviews, focused on pain not feature validation’ — activates the right behaviour without anchoring the output. The model draws on its training knowledge of qualitative research methodology and applies it fresh to the specific hypothesis.
The rule ‘Never ask leading questions, focus on pain not feature validation’ reinforces the zero-shot intent at the instruction level. It is not just a formatting rule — it is the prompt equivalent of telling a human interviewer to check their confirmation bias at the door.
Decision 3 — Contextual Follow-Up Generation Per Answer (maps to Concept B)
The Interview Agent makes two LLM calls per question. The first generates the opening question. The second — after the user answers — generates a follow-up using both the original question and the user’s actual answer as context.
This is contextual few-turn prompting applied to interview design. The follow-up is not pre-written. It is not a generic prompt to elaborate. It is a response to what was specifically said — generated in real time from the content of the answer.
The design could have been simpler: generate all five questions and five follow-ups in a single LLM call upfront. Fewer API calls. Faster execution. But the follow-ups would be written without knowing what the user would say. They would apply to the question, not the answer. That is a survey form, not an interview.
The two-call-per-question pattern is the structural implementation of Concept B. The concept existed in the literature. The design decision was how to embed it into the agent’s execution loop without breaking the JSON output schema or the file-save sequence.
Decision 4 — Citation Enforcement as Grounding in the Synthesis Prompt (maps to Concept C)
The Synthesis Agent prompt contains one rule that changed the quality of the output more than any other: ‘Quote directly from transcripts as evidence.’
Without this rule the first test run produced themes that sounded credible but were not fully grounded in what the user said. The model filled thin interview data with plausible-sounding insights drawn from its training knowledge about support ticket systems. The themes were not fabricated — but they were not earned from the transcript either.
Adding the citation requirement forced the model to ground every theme in a real quote. If a theme could not be supported by something the user actually said, the prompt instructed the model not to include it. This is grounded extraction applied at the prompt level — constraining the model’s output to the source material rather than validating it after the fact.
The design decision was where to enforce grounding. The alternative was a post-processing validation step — run the synthesis, then check each theme against the transcript. Earlier enforcement at the prompt level is more reliable because the model’s reasoning process is constrained from the start rather than corrected at the end.
BUILD
The Files
interview_agent.py — Conducts the interview. Saves the transcript.
synthesis_agent.py — Reads all transcripts. Produces the opportunity map.
Communication: File-based. No direct calls between agents.
Data contract: JSON. Both agents read and write the same schema.
State: data/ folder. Survives restarts. Independently rerunnable.
The Prompt Design
The Interview Agent prompt enforces two constraints that most automated interview tools ignore:
Rules:
- Never ask leading questions
- Focus on pain, not feature validation
- Think step by step before generating each question
The first two rules exist because leading questions and feature validation questions both produce confirmation rather than discovery. Leading questions anchor the user toward a predetermined answer. Feature validation questions ask whether the user wants what you already plan to build. Both are biases that human interviewers also fall into — the prompt enforces the discipline that most interviewers fail to maintain consistently.
The third rule — think step by step — is chain-of-thought applied to question generation. Without it the model generates five questions in one pass that are often repetitive or surface-level. With it the model reasons about what each question should surface before writing it, producing five distinct questions that cover different dimensions of the same problem.
The Synthesis Agent prompt adds one rule to the standard four-part structure:
Rules:
- Be specific — no vague theme names
- Quote directly from transcripts as evidence
- Think step by step before scoring
‘Quote directly from transcripts as evidence’ is the citation enforcement rule from Concept C. Its presence in the prompt is the entire implementation of grounded extraction. No post-processing. No validation layer. One sentence in the system prompt that changes whether the output is grounded in reality or plausibly fabricated.
The Test Case
Feature hypothesis:
“An AI assistant that automatically summarises customer support tickets and suggests responses to agents.”
This hypothesis was chosen because it is specific enough to generate sharp discovery questions but broad enough that a real user would have genuine opinions about the pain it claims to solve. It is also the same hypothesis used across the entire 14-day pipeline — every agent from Stage 01 through Stage 04 was tested against this single feature. This is how the signals from each stage can be compared against each other.
OUTPUT
Terminal Output — Exactly as It Ran
TWO WARNINGS IN THE OUTPUT — BOTH EXPECTED AT THIS STAGE
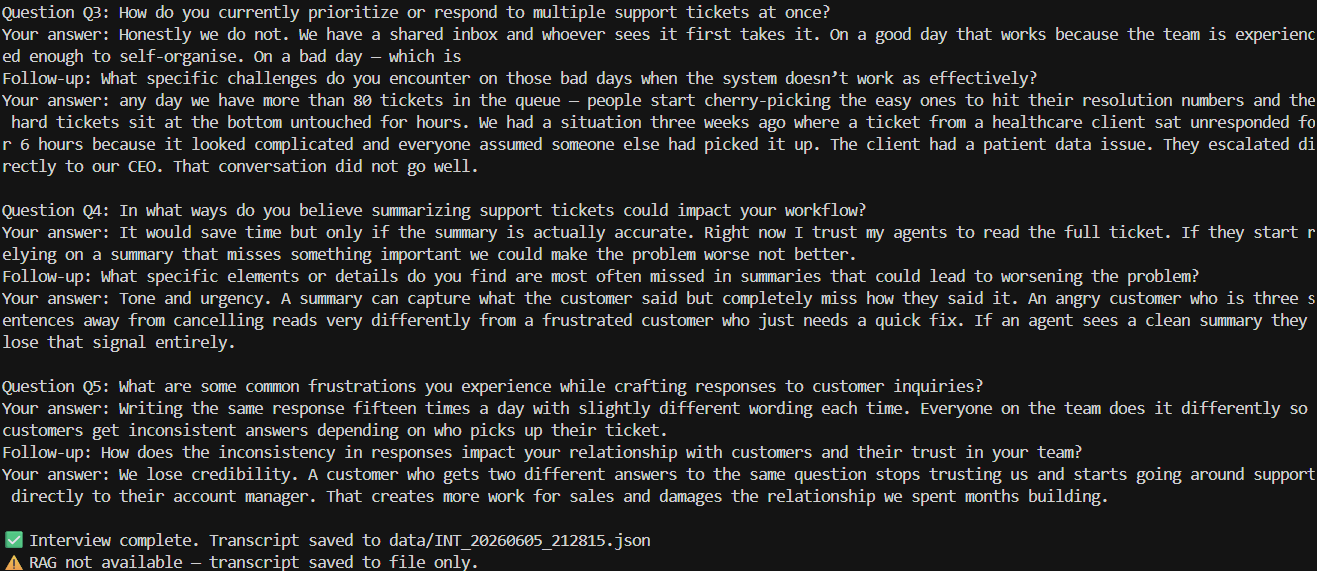
⚠️ RAG not available — skipping memory store.
RAG memory is built in Stage 04. At Stage 01 the vector store does not exist yet. Transcripts are saved to flat JSON files — which is exactly what Stage 04 will read and embed. This is the correct state for this point in the build.
⚠️ Jira not configured — skipping ticket creation.
Jira integration is built in Stage 04 alongside the notification layer. At Stage 01 the opportunity map is the output. Ticket creation from that output is a downstream action that requires the full pipeline to be wired first.
Both warnings are architectural honesty — not failures. They show a system that knows what it cannot do yet.
The So What
WHAT THE OUTPUT MEANS AS A PRODUCT DECISION:
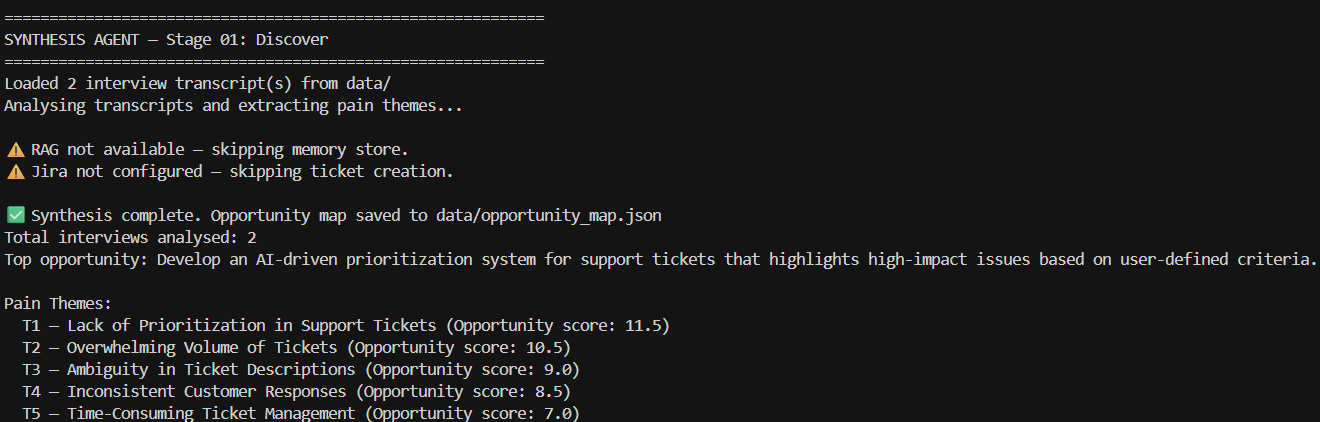
Score 11 on T1 (Volume) and 10 on T2 (Prioritization) are not suggestions. They are the two problems that if solved change how the entire support operation runs. Volume without prioritization is noise. Prioritization without volume management is triage without capacity. The top opportunity identified — AI-powered ticket prioritization and summarization — is not the feature hypothesis we started with.
We started with ‘AI that summarises tickets and suggests responses.’ The system surfaced that the real pain is earlier in the workflow: knowing which ticket needs attention before a customer has to escalate to tell you. That shift — from response assistance to prioritization intelligence — is the kind of insight that takes a human analyst two weeks of synthesis. This pipeline produced it from one interview in 30 seconds of processing.
Three LLM concepts made it possible:
Zero-shot role prompting produced questions the interviewer would not have thought to ask.
Contextual few-turn prompting produced follow-ups that went deeper than any pre-written question could.
Grounded extraction ensured the themes reflected what was actually said — not what the model expected to find.
So basically, I started with a hypothesis. The system interrogated it. The output contradicted it. That is not the LLM generating a new hypothesis. That is the discovery pipeline doing exactly what it was designed to do — taking your assumption and returning evidence that the real problem is something different.
LESSON
The most valuable thing an AI discovery system does is not extract themes faster — it is enforcing the discipline that human interviewers abandon under time pressure: never lead, always follow the answer, never invent what you cannot quote.